ScaleOps is a Hi-Quality, Low-Cost, SOC 2 Certified Secure Data Labeling Company
Are You Ready to Dive Into Your Data Labeling Project?
Types of NLP Text Annotation Services
Information Extraction (IE) is the process of extracting structured information from unstructured text or natural language. This field of NLP invovelves several processes described below.
ScaleOps supports a variety of NLP Text Annotation types. From Named Entity Recognition (NER), Parts of Speech Tagging (POS), and End to End linking, to Entity Disambiguation, Entity Relationship Extraction, Document Classification, and Product Classification, we have you covered.
While these cover the most common types of NLP Annotations for machine learning, our processes are flexible and we can accommodate any kind of annotation that your model training requires.

NAMED ENTITY RECOGNITION (NER)
Named Entity Recognition (NER) – also called entity identification, entity chunking, or entity extraction – involves taking in unstructured text, and, within it, identifying pre-defined entities such as people, places or organizations.

PARTS OF SPEECH (POS) TAGGING
One of the early, and more important, tasks of natural language processing (NLP) is Parts of Speech tagging. POS Tagging involves taking in unstructured text and adding in part of speech tags (noun, verb, adverb for example) to each word within the text.
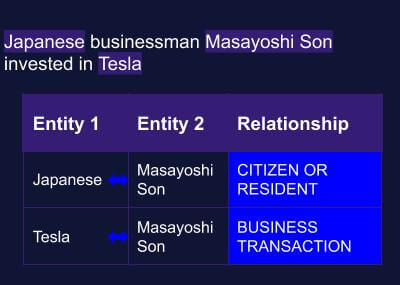
ENTITY RELATIONSHIP EXTRACTION
END TO END ENTITY LINKING
End to End Entity liking consists of two parts Mention Detection, and Entity Disambiguation. Mention Detection is detecting the mention of a pre-defined set of entities. Similar to NER (Named Entity Recognition) this task identifies entities in unstructured text. The second part is Entity Disambiguation, as described next.

DOCUMENT CLASSIFICATION
Document Classification involves assigning one, or multiple, pre-defined classifiers to a document. The classifiers are used to train an NLP machine learning model. Depending on ambiguity around the classifiers, we may even confidence score around each classification to fine-tune the model training.
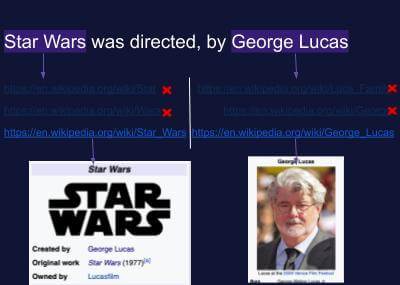
ENTITY DISAMBIGUATION
Entity Disambiguation involves taking in Mention Detection, Named Entity Recognition, entities as input, and mapping them to a trusted Knowledge Base. The goal is to disambiguate, and ensure that the correct context of the entity has been tagged.
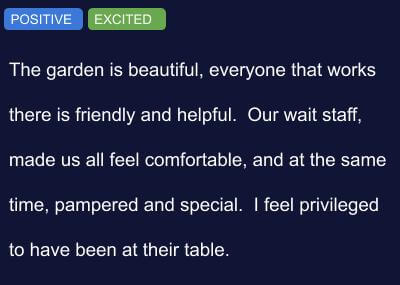
SENTIMENT ANNOTATION
Sentiment Annotation involves extracting the writer’s emotional state from unstructured text.
Why ScaleOps for Text Annotation ?
Deciding to Outsource your AI Model Training is a big decision for any company. Key areas of concern are around:
- Data Security: Will my proprietary data remain secure?
- Quality: Will the text annotations be accurate enough to train my model optimally?
- Cost: Is it going to be cost-effective?
- Scale: Can I start small? Can I scale up fast?
- Turn Around Time: I need my model trained ASAP. How long will this take?
Read below to see why ScaleOps is the best NLP Annotation Services Outsourcing company for you.
Data Security
More about ScaleOps Data Security
ScaleOps is a SOC 2 Compliant AI Training Data Company and leverages serious security controls to ensure the security of your text.
- All employees are background-verified, in-house, full-time employees; We do not crowdsource or allow remote work.
- 24/7 Camera surveillance, on-site Security guards, Access control based on bio-metrics
- We do not allow bags, pens, paper, mobile phones, electronics or USB drives on the floor.
Hi Accuracy
At ScaleOps, we understand that low quality annotations are worse than none at all. Our carefully selected, experienced annotators are trained to make the extra effort to ensure that your text annotations are perfect. Internal HR quality systems assign a share of annotations to multiple labelers to assess individual performance, and use both, sticks and carrots, to control output quality – even at a massive scale.
Low Cost
We strive to deliver the lowest costs in the industry, driven by scale efficiencies, automation, task simplification, and training. We guarantee that you will not find a SOC 2 compliant Secure outsourced data labeling company priced lower than us.
Elastic Scale
No project is too small, or too larger for us. For instance, we have launched projects with one part-time resource and scaled up to 800 annotators. Our ability to take on small projects and our ability to scale fast has been a key differentiator that our clients have benefitted from.
Quick Turn Around Time
We can typically start projects with 10 annotators with 24 hours of notice, and scale up to 100+ annotators within 2 weeks.
With ScaleOps, you can go from the first conversation to data ready model training in record time.
Turn-Key Delivery
From training and managing your team of annotators to upscaling, addressing questions, and assimilating results, ScaleOps has an efficient layer of middle management that will take you from project requirements to results with little to no effort on your end. Just provide your requirements and data to your Client representative. We’ll take it from there.

Text Annotation Tools
We have our own Text Annotation Tool that is able to text classification, sequence labeling, named entity recognition (NER), entity disambiguation, sentiment annotation and more.
ScaleOps also has expereince with several open source and paid text annotation tools such as Doccano, TagTog, brat, Inception, and more.
Depening on works best for training client’s AI Machine Learning Algorithms, we can use our own too, or a third-party NLP Text Annotation Tool.

Output Formats – JSON, XML, CSV, EXL
.. or any other proprietary format you want
JSON, XML, CSV, and Excel are the primary output formats we deliver results of our NLP Tagging Services.
Applications of Natural Language Processing (NLP)
Text Annotation is primarily used to enable Machine Learning Algorithms to understand human languages. Applications for AI Machines that understand human languages include: Machine Translation, Speech Recognition, Sentiment Analysis, Question Answering, Document Summarisation, Chatbot Training, Market Intelligence, Text Classification, Spell Checking, and Character Recognition.
Machine Translation
Natural Language Processing
Natural Language Processing (NLP) is a field of Deep Learning that enables AI to understand written language. Click here for ScaleOps’ NLP Text Annotation Services, which include Named Entity Recognition(NER), Parts of Speech Tagging (POS), End to End Entity Linking, Entity Disambiguation, Entity Relationship Extraction, Document Classification, Sentiment Annotation and more.
Video Annotation
Tagging and Categorisation, 2D and 3D Bounding Boxes and Semantic segregation for Self Driving cars and other computer vision projects
Audio Annotation
Subscribe For Updates